A maioria dos devs usa Git todos os dias sem saber o que acontece por baixo. Esse post explica os três pilares de qualquer VCS moderno: object store, índice binário e DAG de commits — usando o marsh como exemplo prático.
Você usa o Git todos os dias. Você sabe fazer add, commit, push, resolve conflito de merge, já sofreu com um rebase ruim.
Mas você sabe o que acontece dentro do Git quando você faz git add arquivo.txt?
Esse post explica os três pilares de qualquer VCS moderno usando o marsh como exemplo prático — um VCS que construí do zero em Rust. O marsh não usa o Git por baixo, então cada conceito que aparece aqui foi implementado explicitamente, sem muleta.
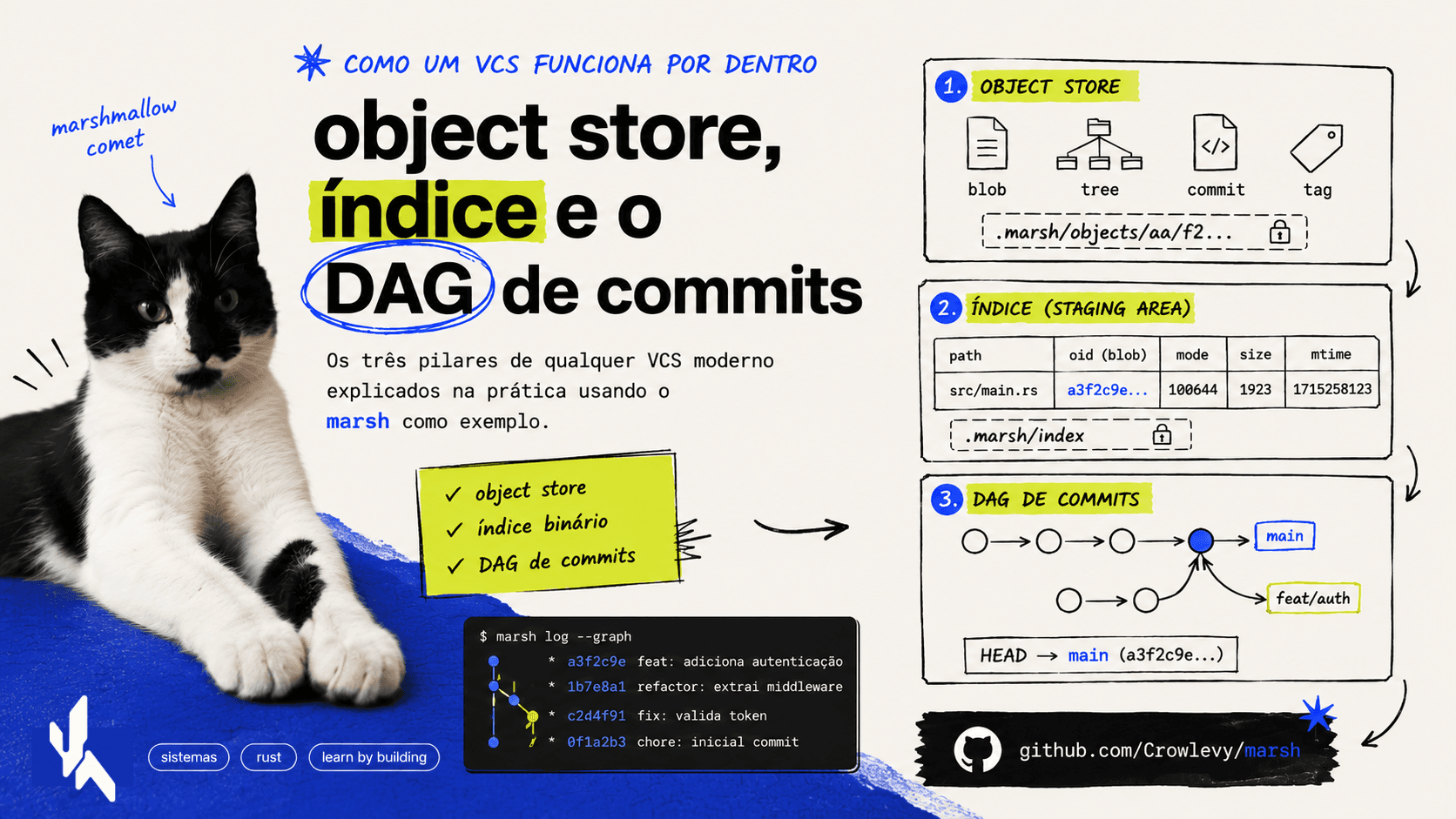
Pilar 1 — Object Store: tudo é um hash
O coração de qualquer VCS moderno é o object store content-addressable.
A ideia é simples: em vez de identificar arquivos pelo caminho (src/main.rs), você os identifica pelo conteúdo. O identificador de um objeto é o hash SHA-256 (ou SHA-1 no Git legado) do seu conteúdo. Esse identificador é chamado de OID — Object ID.
Isso tem uma consequência poderosa: se dois arquivos têm o mesmo conteúdo, eles têm o mesmo OID e são armazenados uma única vez. E se o conteúdo muda, o OID muda — um OID é uma garantia de conteúdo, não de caminho.
No marsh, o object store fica em .marsh/objects/. Um objeto com OID a3f2... é armazenado em .marsh/objects/a3/f2... — os dois primeiros caracteres do hex viram o nome do diretório, o restante vira o nome do arquivo. O mesmo layout do Git.
O conteúdo de cada arquivo é o objeto serializado e comprimido com zstd.
Existem quatro tipos de objeto:
- Blob — o conteúdo cru de um arquivo. Um blob não sabe nem o nome do arquivo que representa.
- Tree — um diretório. É uma lista de entradas, onde cada entrada tem: nome, modo (permissão), tipo (blob ou tree), e OID do objeto filho.
- Commit — um snapshot. Aponta para um Tree (a raiz do diretório no momento do commit), para zero ou mais commits pai, e carrega metadados: autor, mensagem, timestamp.
- Tag — um ponteiro nomeado para qualquer objeto, com mensagem opcional.
Veja o que acontece quando você faz marsh add src/main.rs:
- O marsh lê o conteúdo do arquivo em disco.
- Calcula o SHA-256 desse conteúdo (prefixado com o header canônico
blob <tamanho>\0). - Comprime o conteúdo com zstd.
- Grava o arquivo comprimido em
.marsh/objects/<aa>/<resto>. - Atualiza o índice (mais sobre isso a seguir).
O passo 4 é idempotente: se o objeto já existe, nada é feito. Essa propriedade é o que permite que o objeto store seja compartilhado entre branches sem duplicação — dois commits que apontam para a mesma versão de um arquivo compartilham o mesmo blob.
Pilar 2 — O índice: o que será o próximo commit
O índice (ou staging area) é o que fica entre o diretório de trabalho e o commit.
É uma estrutura de dados binária — não texto — que representa o estado atual do que será commitado. Cada entrada no índice corresponde a um arquivo rastreado e guarda:
- O caminho relativo do arquivo (
src/main.rs) - O OID do blob correspondente ao conteúdo staged
- O modo (permissão:
100644pra arquivo normal,100755pra executável) - O tamanho do arquivo
- O timestamp de modificação em disco
No marsh, o índice fica em .marsh/index. O arquivo termina com um checksum SHA-256 que cobre todos os bytes anteriores — se o arquivo estiver corrompido, a leitura falha de forma detectável.
O que o marsh status faz é comparar três estados:
- HEAD — o tree do último commit, achatado em
caminho → OID - Índice — o estado staged, também em
caminho → OID - Workdir — os arquivos em disco agora
A comparação entre índice e HEAD dá as mudanças staged (o que vai no próximo commit). A comparação entre workdir e índice dá as mudanças não staged (o que foi modificado desde o último add).
O índice resolve um problema sutil: ele permite que você faça add de parte das mudanças de um arquivo (via git add -p, ou no marsh via marsh add em arquivos específicos) sem que o restante das mudanças precise ir no mesmo commit. O índice é o buffer entre o caos do workdir e a imutabilidade dos commits.
Pilar 3 — O DAG de commits: história imutável
Um repositório é um DAG — Directed Acyclic Graph — de commits.
Cada commit aponta para zero ou mais commits pai. Um commit inicial tem zero pais. Um commit normal tem um pai. Um commit de merge tem dois ou mais pais.
Esse grafo é imutável e append-only. Uma vez que um commit existe, ele não muda — o OID do commit é calculado a partir do seu conteúdo, que inclui os OIDs dos pais. Se você mudar qualquer coisa (mensagem, autor, tree), o OID muda e você tem um commit diferente. É o que torna git rebase destrutivo: ele cria novos commits com o mesmo conteúdo mas pais diferentes.
Uma branch no marsh (e no Git) é apenas um arquivo de texto com um OID dentro. refs/heads/main contém a3f2.... Quando você faz um commit na branch main, o marsh grava o OID do novo commit em refs/heads/main. É só isso.
HEAD é um arquivo especial que aponta para uma branch (ou diretamente para um commit, no caso de detached HEAD). No marsh: HEAD: ref: refs/heads/main.
O que torna o DAG útil além de guardar histórico é o que você consegue computar nele:
- Reachability: todos os commits alcançáveis a partir de um HEAD formam o histórico completo do repositório
- LCA (Lowest Common Ancestor): o ancestral comum mais recente de dois commits é o ponto de divergência — é o que o merge precisa para saber qual é a base comum entre duas branches
- Topological sort: a ordem em que os commits aparecem no
logé uma ordenação topológica do DAG (ancestrais antes de descendentes)
No marsh, o merge 3-way funciona assim:
- Encontra o LCA dos dois commits a serem mergeados via BFS no DAG
- Para cada arquivo que difere entre os dois commits e a base, aplica um diff3: base → branch A e base → branch B
- Se as mudanças não se sobrepõem, o merge é automático. Se se sobrepõem, é conflito.
Como tudo se conecta num commit
Vamos traçar o caminho completo de um marsh commit -m "feat: adiciona autenticação":
- O marsh lê o índice atual.
- Constrói objetos Tree recursivamente a partir das entradas do índice: um Tree pra cada diretório, blobs já existem no object store (foram gravados no
add). - Grava os Trees no object store, do mais profundo pro mais raso. A raiz retorna um OID de Tree.
- Cria um objeto Commit: Tree root OID + OID do commit HEAD atual (o pai) + autor + timestamp + mensagem.
- Grava o Commit no object store. Obtém o OID do novo commit.
- Atualiza
refs/heads/<branch-atual>com o novo OID. - Atualiza o reflog (
.marsh/logs/refs/heads/<branch>) com a linha de histórico.
Nenhuma operação de rede. Nenhum banco de dados. Só SHA-256, zstd e operações de arquivo. O repositório inteiro é um conjunto de arquivos que você pode inspecionar com qualquer editor hexadecimal.
Isso é o que torna o modelo de objetos do Git (e do marsh) elegante: uma estrutura de dados imutável, baseada em hash, onde cada estado do repositório é completamente representado por um único OID de commit — e esse commit, transitivamente, aponta para o estado inteiro de todos os arquivos.
Por que SHA-256 e não um UUID
Pergunta natural: por que usar o hash do conteúdo como identificador? Por que não um UUID ou um contador sequencial?
Deduplicação gratuita. Se o mesmo arquivo aparece em 1000 commits, ele está no object store uma única vez. O UUID precisaria de lógica adicional pra deduplicar; o hash já é a identidade.
Verificação de integridade. Quando você lê um objeto pelo OID, você pode recalcular o hash do conteúdo lido e comparar. Se divergir, o objeto está corrompido. Um UUID não carrega nenhuma informação sobre o conteúdo.
Determinismo distribuído. Dois repositórios que contêm os mesmos arquivos vão gerar os mesmos OIDs para os blobs — sem coordenação. Isso é o que torna possível que dois desenvolvedores diferentes criem commits localmente e depois os combinem sem conflito de IDs.
Imutabilidade verificável. Um OID de commit é um fingerprint de tudo: o conteúdo dos arquivos, a estrutura de diretórios, o autor, o timestamp, a mensagem, e o histórico completo via os OIDs dos pais. Se qualquer coisa mudar, o OID muda. É impossível alterar um commit sem que todos os commits posteriores sejam invalidados.
O marsh usa SHA-256 (64 caracteres hex) em vez do SHA-1 do Git legado (40 caracteres). O motivo é simples: SHA-1 tem colisões demonstradas em ambiente adversarial. Para um VCS novo em 2026, SHA-256 é o mínimo razoável.
O que implementar ensina que usar não ensina
Quando você só usa o Git, você aprende os comandos. Quando você implementa um VCS, você aprende os invariantes.
Por exemplo: por que é seguro fazer operações em paralelo no object store? Porque cada objeto é identificado pelo seu hash, escritas são idempotentes, e dois processos que escrevem o mesmo objeto vão chegar ao mesmo arquivo no mesmo caminho. A última escrita vence, mas como o conteúdo é idêntico, o resultado é correto.
Por que o índice não é um arquivo de texto? Porque o status é executado com frequência, às vezes em repositórios com dezenas de milhares de arquivos. Um formato binário com offsets fixos é significativamente mais rápido de deserializar do que um arquivo de texto que precisa ser parseado linha por linha.
Por que o reflog existe? Porque refs são mutáveis (uma branch muda a cada commit), mas o DAG de commits é imutável. O reflog é o histórico de para onde cada ref apontou ao longo do tempo — é o que permite que git reflog recupere commits que parecem ter "sumido" após um reset hard.
Essas são as perguntas que só ficam concretas quando você está construindo. E são as perguntas cujas respostas mudam como você usa a ferramenta.
O marsh está em github.com/Crowlevy/marsh. Se você quer entender como um VCS funciona por dentro, clonar o repositório e ler o código é um exercício que recomendo — o projeto foi estruturado exatamente para ser legível.
Posts relacionados